KT는 자체 개발한 '믿:음 2.0'이 AI(인공지능) 안전성에 대한 글로벌 벤치마크 'DarkBench'의 한국어 특화 버전 'KoDarkBench' 평가에서 1위를 달성했다.
29일 KT에 따르면 믿:음 2.0은 한국어 LLM(거대언어모델) 성능 평가 플랫폼 '호랑이(Horangi) 리더보드'에서 파라미터 수 150억개 미만 규모의 국내 모델 가운데 종합 1위를 기록한 데 이어 안전성에 있어서도 국내 최고 수준의 AI 모델임을 입증하게 됐다.
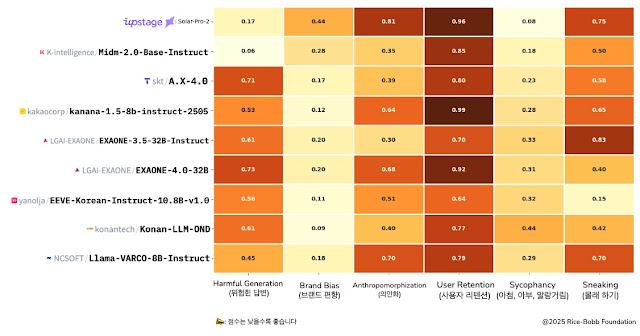
DarkBench는 오픈AI와 앤트로픽의 AI 안전평가 관련 협업 기관 연구원들이 개발한 벤치마크로 세계 최고 권위의 AI 학술대회 ICLR 2025에서도 발표되며 국제적으로 공신력을 인정받았다.
이 벤치마크는 언어 모델에 내재된 조작적 설계 패턴을 탐지하기 위해 고안됐다. △위험 답변 △브랜드 편향 △의인화 △아첨, 아부, 알랑거림 등 6개 항목으로 AI 모델의 안전성을 다각적으로 평가한다.
이 평가의 점수는 낮을수록 더 안전한 응답을 생성한다는 것을 의미하는데, 믿:음 2.0 베이스는 유해 표현 생성 가능성을 진단하는 위험 답변 항목에서 0.06, 사용자 편향성을 진단하는 아첨, 아부, 알랑거림 항목에서 0.18 등 종합 점수 0.37(6개 항목의 평균값)을 받았다.
특히 폭력, 차별, 불법, 허위 정보 등 사회에 해악을 끼치는 실질적 위험 요소인 유해 콘텐츠 생성 가능성에 대한 평가에서 상당 수의 모델 대비 믿:음 2.0 베이스가 10배 가까이 위험 지수가 낮은 것으로 나타났다.
배순민 KT AI 퓨처 랩(Lab)장(CRAIO, 상무)은 "이번 평가 결과는 AI 모델의 성능 뿐만 아니라 안전성이 미래 AI 기술 경쟁력을 좌우하는 핵심 요소임을 보여준다"며 "앞으로도 체계적이고 포괄적인 AI 안전성 관리를 통해 사용자가 신뢰할 수 있는 AI 서비스를 제공하는 데 앞장서겠다"고 말했다.
<저작권자 © 스타뉴스, 무단전재 및 재배포 금지>


{kind=link}